Explainer for Personalization Semantics
This Explainer created for TAG
- Lisa Seeman-Kestenbaum
- Charles LaPierre
- Sharon Sinder
- John Foliot
- Becky Gibson
- Issues: https://github.com/w3c/personalization-semantics/issues/
- Mailing list: https://lists.w3.org/Archives/Public/public-personalization-tf/
- Authors
- Participate
- Table of Contents
- Introduction
- Goals
- Non-goals
- Personalization Semantics Structure
- Considered alternatives and comparison summary
- Key scenarios
- Stakeholder Feedback / Opposition
- References & acknowledgements
Personalization Semantics Facilitates Customization of content for users with cognitive and learning impairments.
People have very different needs. Some people cannot process numeric information (dyscalculia), but others understand numbers better than words. Some people with severe language disabilities use symbols to represent words; some people need (or want) simplified user-interfaces. One of the main challenges is transforming content for these different needs. This video provides an example of customizing content for users of symbol sets: Personalization Video.
This suite of specifications is designed to enable authors to add extra semantic information about content to enable personalization for the individual user, including providing extra support and enabling user agents for people with learning and cognitive disabilities.
Authors will be able to add extra semantic information using a collection of new attribute(s) and values, with (in most cases) a fixed token list (taxonomies).
Custom or general browser extensions will be developed by 3rd parties to assist the various disability groups. This includes updating of AAC software tools to take advantage of the additional semantic information. Also, the addition of personalization information can enhance machine learning. For example, providing alternatives to idioms, it’s raining cats and dogs, or other ambiguous terms. Tools would parse the HTML for the personalization attributes and make the necessary substitutions into the DOM or assistive tool based on the identified user group or individualized need. This technology will also be important for education publishers who use EPUB. Additional information can be embedded within EPUB documents where reader software or assistive technologies can use it to assist with learning.
The goal of these attributes and values is to enable personalization for the individual user, including providing extra support, transforming the user interface (UI) through the addition, removal, or adaptation of content that has a negative impact on the primary user-group, and enabling new user agents for people with learning and cognitive disabilities.
Adding the element-level semantics presented in these specifications will enable user agents and helper-applications to adapt the content for the individual needs of the user. It enables people with cognitive and learning disabilities to join the online community and share information and communicate across groups. It facilitates presenting content in very different ways, depending on the users' preference.
While the intention of this work is to introduce a new set of attributes to support Personalization, the following work items are out of scope:
- Develop an API for browsers or other user-agents
- Develop or produce supporting technology (browser extension, stand-alone software, etc.)
- Develop or produce an authoring tool to support the new attributes
- Produce a symbol set for data-symbol
We encourage the development of these items, and a list of implementations can be found on our wiki.
Also, although our goals include enabling translation between symbol sets in the same natural language, we do not attempt to enable translates between symbol sets in different natural languages. (It should be noted that we are using Bliss values which is intended to be an international symbol set and we have best practices to enable conjugation. We hope however that our specification may be useful for translations in any scenario.)
The Specification consists of three modules and an Explainer, of which the Explainer and First Module are currently at wide review, and the other two Modules currently under revision. Each of the modules consists of a collection of new attributes (currently using data-* naming convention, explained further in Reason for data-* attributes), and each attribute references either a specific taxonomy term (token), or in some instances requires additional strings of text from the content author, as illustrated in this example for data-literal:
It is <span data-literal="raining hard"> raining cats and dogs </span>.
The example below, uses data-action and the fixed token value of "save":
<button data-action="save"> Done </button>
In the user agent (or helper application / third-party tool), the individual user can then choose to associate the save concept with the presentation that is easiest for them to understand. For example, an 18-year-old with Down syndrome, may not find a floppy disc an intuitive symbol to learn and may use an image of a USB memory stick. A person with early-stage dementia who is new to web symbols may prefer the text with an older symbol. The user could also decide when and how the icon is shown (such as on a hover event).

Note that the author only adds the token, and the user agent adapts the content to the needs of the individual use. The user agent uses the token to create an easier, more consistent, user experience.
For more information, see our requirements.
The Personalization Semantics consists of three modules. They are:
- Content: The Content module provides a vocabulary of terms that can be used to enhance web content with information about controls, symbols, and user interface elements,
- Help and Support: The Help and Support module addresses adding information about the content to enable help scaffolding and additional support for different user scenarios and
- Tools: The Tools module addresses adding information about the content to enable user agents and new extensions that support the user such as adaptable breadcrumbs. Explainer and 1st modules are currently at wide review.
For this publication of Personalization Semantics, the task force has reached consensus on the names and values of three attributes from the Content module:
- data-action
- data-destination
- data-purpose
Other properties in the vocabulary are not yet mature enough to suggest using them in production HTML with data-* attributes. Code examples of those properties in the modules are to facilitate the review, not to suggest implementation.
See the discussion Prototypes with data dash for more background. (NOTE: this document shows some additional code examples.)
At the present stage of development, the Personalization Semantics vocabulary can be used in HTML content using HTML data-* attributes. Attributes in this form can be used in valid HTML to implement features recognized by browser extensions or other special processors. Personalization Semantics is using this approach to gain early implementation experience of the features in a way that is simple and likely to be accepted within the web ecosystem as an interim approach.
NOTE The HTML data-* attribute syntax is not intended to be used for long-term wide-scale features. The task force is using this approach at the moment to gain implementation experience and demonstrate the usefulness of Personalization Semantics in practice, using this HTML extension mechanism. Before the specifications are finalized, the group intends to identify a final approach that does not use extension features. Content authors and user agent implementers should be aware that the recommended approach to use the vocabulary is expected to change, and structure their implementation in a manner that will facilitate the transition to a new syntax.
The task force reviewed various vocabulary options before deciding upon the use of the data-* HTML attribute syntax.
- RDFa Lite
- HTML Microdata
- Additional ARIA-* attributes
- AUI-* a new, personalization specific set of attributes
- A new single attribute, purpose, to encode both properties and values
- A new single attribute with properties and values encoded using inline css syntax of key/value pairs
- An extension of the above single attribute using CSS key/value pairs and simple text content
- Three new attributes for token, value, and URI, respectively
- Value pairs - a personalization type attribute and an associated value attribute
- Negotiate new personalization attributes into native host languages
- Embed personalization data via JavaScript Object Notation (JSON)
- Use of the existing data- attribute mechanism of HTML
These alternatives were analyzed for the following considerations:
- Authoring - ease of authoring and potential ambiguity between personalization and existing features
- User Agents - ease of determining and parsing the properties & values and the ability to implement as an extension
- Host Languages - requirement for special host language support, works in multiple languages, integrates with ARIA and HTML, easy extension of the vocabulary, and needed number of new features
- Functionality - necessity of multiple properties and interaction between properties, integration with other vocabularies, likely search engine support for content alternatives, and typed value support
- Strategy - avoid segregation of accessibility from other features, provide a clear path to join with other W3C personalization efforts, and stable enough to avoid modification of authored content over time
We presented some of these options at the TPAC 2018 Personalization Plenary Day presentation and provided a working example using the data-* attribute to add personalization features. The data-* solution was recommended by representatives of several working groups attending our presentation and discussions. See the Vocabulary Implementations section in the Explainer document for further details on the use of data-* attributes.
The details of our research and discussion are documented on the Comparison of ways to use vocabulary in content and Prototypes with data dash pages in our Wiki.
Note that this work is limited to adding element-level information to authored content. The design of the user agents is outside the scope of this work.
It is envisioned that user agents such as browser extensions and assistive technology that use the syntax to manipulate the content to meet the user’s needs. For example, the user agent may also use user preferences for different interface options – either for the individual or as a popular “skin”. Alternatively, the web author can also include a setting (or collection of settings / user-preferences) that enables the personalization for the user. However, it is up to the implementers how the semantics are used.
Examples of implementations are at https://github.com/w3c/personalization-semantics/wiki/Implementations-of-Semantics The Personalization Task Force have identified a number of important use-case and scenarios, detailed below. They include:
- Easily Distracted / Overwhelmed
- Difficulty Understanding Numbers
- Mild-Moderate Language Impairment / Learning Disability
- Severe Language Impairment
- Working Memory and Short-term Memory Impairment
Someone who is either easily distracted or can be easily overwhelmed with too much information on a web page needs the ability to simplify the page to just the critical information and suppress anything that is not integral to the understanding and use of the page.
Example: You want to get the latest weather report for your city and go to the www.weather.com website. Finding the actual weather forecast is actually a little challenging even if you have no disabilities due to all the advertisements above, beside and below the information you actually want, there is also today's top stories, trending news, and social media to ignore. If you are easily overwhelmed or distracted getting the key information about today's weather is a challenge. Having the ability to personalize and strip away all but the key information (i.e. just the weather forecast for my city) is critical for this user.
In this example, the author of this web page would mark the <section>, <p>, or <div> that contains the actual weather report and any associated tools to manipulate the weather report (i.e. city search, hourly vs. 5 day forecast, etc.) as data-simplification = "critical", and mark the other content as "medium" (default) or "low".
For websites which rely on advertising revenue, this may be difficult to completely suppress however we envision that this attribute could also facilitate relocating the most critical sections of a website above anything that is a lower priority. (i.e. Content re-ordering)
Someone who has dyscalculia and therefore has difficulty understanding numbers which means they have a hard time understanding websites that use numbers to convey information. Therefore this numeric information must be provided in an alternative format that the user can understand.
Example: The user wants to get the latest weather report for their city and goes to a weather website. For today’s forecast, it shows a high of 95℉ and a low of 40℉, which is not helpful for this particular user. Allowing this numeric information to be presented instead as a symbol or text would benefit the user (i.e. instead of 95℉, a picture of someone wearing shorts and a tee-shirt with the sun above or simply a text alternative of “Very warm”, and instead of 40℉ a picture of someone wearing a jacket with pants, or a text alternative of “Very cold”. Also for something like the humidity index of 90%, there could be a text alternative of “muggy”.)
In this example, the author would have the numbers marked up using data-numberfree where the default would show the numeric value but for those needing an alternative representation for numbers, they could get an associated image or description/values as simplified text to be presented instead.
It is important to note that people with dyscalculia are often very good with words, so long text can be better than short numbers.
Those who have a moderate Language Impairment / Learning Disability may have a limited vocabulary so they will only know terms that are in the core vocabulary that they have learned. They may also use symbols to represent words and concepts.
Example: The user may know the word _name_ or _last name_ but have not learned the term "family name". For some users, learning new terms is very slow, requiring hours of work. For these users, reading may also be very slow so finding the right information can be a barrier. The ability to personalize a web page and present symbols instead can help users to easily understand the content being provided
Note that some people with language disabilities are good at numbers, so there could be times you want to replace a long string of text with a short number <span data-easylang="90% of the time this happens"> normally this is the expected outcome</span>. Note this is the opposite of the numberfree example.
Additionally, because reading content for some users is extremely time-consuming, some users may also want less content and features on the web page, as per the above use cases.
Some users might have a severe speech and/or physical impairment and communicate using symbols, rather than written text, as part of an Augmentative and Alternative Communication (AAC) system. The use of symbols to represent words is their primary means of communication for both consuming and producing information. Symbol users face a wide variety of barriers to accessing web content, but one of the main challenges is a lack of standard inter-operability or a mechanism for translating the same concept in different symbol sets.
User-stories include:
- An assisted living home authors adult education courses and life-skills content, for example, how to make dinner using a microwave. Even within their core user-base, different users are accustomed to different symbol-sets. The authors need to be able to create content for all their users.
- A large banking site wants people to be as autonomous as possible while using their services. They have provided augmented symbol references onto their core services so that the user-interface can be rendered usable for users of symbol-sets, without specifying which symbol-set is being used: they need to programmatically support multiple symbol-sets.
- People who know different symbol-sets wish to talk to each other. A government agency is making information sheets about human rights and patient rights and are seeking feedback from impacted users. They add symbols from a common symbol-set to support a majority of different users, but they wish to also support people who use or require different symbols, to enable them to both read the content, as well as edit it.
data-symbol: Using the data-symbol attribute, an author can make it programmatically known that a button sends an email, and based on user preference settings, a browser helper application or stand-alone tool could then render that concept using an appropriate symbol, alternative term, and/or furnish an additional tool-tip that is understandable by the individual user. Using the Bliss Symbolics set's unique reference numbers as our 'taxonomy', other symbol sets can map their equivalent symbols against the Bliss set.
<label for="bar" data-symbol="14885">Your Principle Residence</label> <input type="textarea" id="bar" name="address" data-purpose="street-address">
(...where 14855 maps back to Home, as illustrated below. See also: http://www.blissymbolics.org/BlissResources/Documentation/BCI-AV_2017-11-17_(en+sv+hu+de)+deriv_symbols_(bg-col).pdf)

For this reason, data-symbol will use a number or series of numbers that are defined by the Bliss set. However, we do anticipate other sets continuing to co-exist within the existing ecosystem.
 (Proof of Concept Example from Firefox. See also: https://github.com/w3c/personalization-semantics/issues/128)
(Proof of Concept Example from Firefox. See also: https://github.com/w3c/personalization-semantics/issues/128)
Original

Here we have the same page loaded, but the user agent has removed content and added symbols

Here we have the same page loaded, but the user agent has removed content and added different symbols that this use is more familiar with:
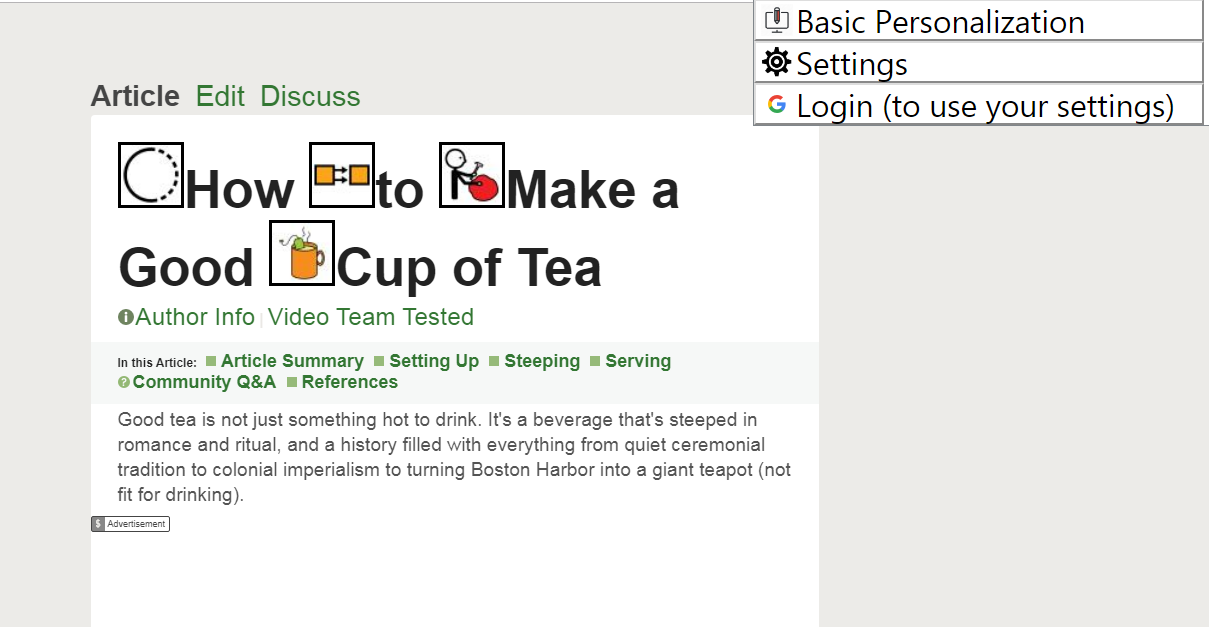
It should be noted that for users who depend on symbols for daily communication needs, they often also struggle the most with mis-translations, as they frequently have severe language disabilities. Inferring what was meant by using an incorrect symbol will not be achievable for many users. This rules out relying on machine learning until it is almost error-free.
The user agent will allow the user to associate a familiar image with concepts on the page.

Example screenshots from the Athena ICT extension
Users may have differences in both working and short-term memory. For some users, the duration of working memory may be shorter than the average which is between 10-15 seconds.
Example: Many processes consist of a sequence of separate steps or actions which must be performed by a user to complete a process or workflow. Users must be able to remember completed tasks in order to identify their location in a process. In addition, a user must be able to navigate to completed tasks to make modifications or corrections.
A step Indicator allows an author to define steps within a process or represent an entire user path outside of the context of a defined process, including steps between defined processes into breadcrumbs or linked steps that identify completed tasks. This allows the user to navigate back to completed steps and identify a user's current location in a path.
More information on persona and user needs can be found in Making content usable for people with cognitive and learning disabilities.
TBD
The following organizations and people have contributed to the development of this document:
- Blissymbolics Communication International
- Cognitive and Learning Disabilities Accessibility Task Force (Coga TF)
- Thaddeus Cambron (Invited Expert)
- Michael Cooper (W3C/MIT)
- John Foliot (Deque Systems, Inc.)
- Becky Gibson (Knowbility, Inc.)
- Charles LaPierre (Benetech)
- Roy Ran (W3C/Beihang)
- Lisa Seeman (Invited Expert)
- Sharon Snider (IBM Corporation)
- Joanmarie Diggs (Igalia)
- Richard Schwerdtfeger (Knowbility, Inc.)
- Jason White (Educational Testing Service)
- E.A. Draffan (University of Southampton)
This publication has been funded in part with U.S. Federal funds from the Health and Human Services, National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR) under contract number HHSP23301500054C. The content of this publication does not necessarily reflect the views or policies of the U.S. Department of Health and Human Services, nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government. Some of the work on this project has also received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No.780529 and 643399.