NIFI-4521 MS SQL CDC Processor #2231
Conversation
| import java.util.ArrayList; | ||
| import java.util.List; | ||
|
|
||
| public class MSSQLCDCUtils { |
There was a problem hiding this comment.
I didn't see any (non-constant) member variables, seems like all the variables and methods could be static?
There was a problem hiding this comment.
Yes and no. The main code would be fine with just static's, but the unit test needs to override certain methods. (ref MockCaptureChangeMSSQL in CaptureChangeMSSQLTest)
| MSSQLColumnDefinition col = new MSSQLColumnDefinition(jdbcType, columnName, columnOrdinal, isColumnKey==1); | ||
| tableColumns.add(col); | ||
| } | ||
| } catch (SQLException e) { |
There was a problem hiding this comment.
You don't really need this catch block to rethrow the same exception, maybe cast it to CDCException or replace the catch block with an empty finally block?
| } | ||
| } | ||
|
|
||
| public void ComputeCapturePlan(Connection con, MSSQLCDCUtils mssqlcdcUtils) throws SQLException { |
There was a problem hiding this comment.
Nitpick on leading capital letter in method name
| public static final String INITIAL_TIMESTAMP_PROP_START = "initial.timestamp."; | ||
|
|
||
| public static final PropertyDescriptor RECORD_WRITER = new PropertyDescriptor.Builder() | ||
| .name("record-writer") |
There was a problem hiding this comment.
Very awesome that you are using the Record API here!
...-mssql-processors/src/main/java/org/apache/nifi/cdc/mssql/processors/CaptureChangeMSSQL.java
Show resolved
Hide resolved
| } | ||
|
|
||
| return new PropertyDescriptor.Builder() | ||
| .name(propertyDescriptorName) |
There was a problem hiding this comment.
Nitpick to add displayName() as well, I know they're the same but this way it won't show up in any searches for PropertyDescriptors that have name() but not displayName()
| protected List<PropertyDescriptor> descriptors; | ||
| protected Set<Relationship> relationships; | ||
|
|
||
| protected final Map<String, MSSQLTableInfo> schemaCache = new ConcurrentHashMap<String, MSSQLTableInfo>(1000); |
There was a problem hiding this comment.
Should this be configurable due to memory concerns? If each MSSQLTableInfo is likely to be small (just a few short strings or whatever), then this number is probably fine.
There was a problem hiding this comment.
There actually isn't really a reason to have an initial value at all. I copied this from the revolving cache used in other processors, but removed the cleaning part of the code that limits the size of the cache. Since this processor does not allow inputs, the size of the schema cache doesn't need to worry about growing forever like some other processors that allow expression language for the table name, and an input flowfile, do.
| final DBCPService dbcpService = processContext.getProperty(DBCP_SERVICE).asControllerService(DBCPService.class); | ||
|
|
||
| final boolean takeInitialSnapshot = processContext.getProperty(TAKE_INITIAL_SNAPSHOT).asBoolean(); | ||
| final int fullSnapshotRowLimit = processContext.getProperty(FULL_SNAPSHOT_ROW_LIMIT).asInteger(); |
There was a problem hiding this comment.
Would have to add ".evaluateAttributeExpressions()" here if you add EL support to this field (see comment above)
| @InputRequirement(InputRequirement.Requirement.INPUT_FORBIDDEN) | ||
| @Tags({"sql", "jdbc", "cdc", "mssql"}) | ||
| @CapabilityDescription("Retrieves Change Data Capture (CDC) events from a Microsoft SQL database. CDC Events include INSERT, UPDATE, DELETE operations. Events " | ||
| + "for each table are output as Record Sets, ordered by the time, and sequence, at which the operation occurred.") |
There was a problem hiding this comment.
Should probably mention here that in a cluster, this processor is recommended to be run on the Primary Node only.
| @Test | ||
| public void testRetrieveAllChanges() throws SQLException, IOException { | ||
| setupNamesTable(); | ||
|
|
There was a problem hiding this comment.
Line 215 is not blank, so it throws a CheckStyle violation
There was a problem hiding this comment.
I've never been able to get CheckStyle to run on my unit tests. It's like IntelliJ doesn't recognize them as valid targets for the plugin. Thanks.
| " OBJECT_NAME(object_id) AS [tableName], \n" + | ||
| " SCHEMA_NAME(OBJECTPROPERTY(source_object_id, 'SchemaId')) AS [sourceSchemaName],\n" + | ||
| " OBJECT_NAME(source_object_id) AS [sourceTableName] \n" + | ||
| "FROM [cdc].[change_tables]"; |
There was a problem hiding this comment.
Microsoft recommends not to refer system table like change_tables instead use sys.sp_cdc_help_change_data_capture. https://docs.microsoft.com/en-us/sql/relational-databases/system-tables/cdc-change-tables-transact-sql
There was a problem hiding this comment.
Yes, this is true. Two reasons why I did not go this route:
- I could not find any way to build unit tests that required SQL stored procedures in a reliable way. I'm running this processor in our production environment and it's quickly becoming more and more important. I need to ensure I can run unit tests on it. If you can provide me with some guidance on building ApacheDB stored procedures and integrating them into unit tests I can take a look, but then there is the permissions issue...
- This stored procedure requires additional permissions beyond select permissions. I use a read-only account from NiFi with limited permissions, and when I run this procedure with no arguments it returns no rows of data because the account is not able to retrieve some of the required data this SP needs. This same account is able to run with this processor. A lot of ETL accounts are severely limited when it comes to permissions for obvious reasons, it felt best to me to support those scenarios.
| @@ -175,10 +175,12 @@ private static DataType getDataType(final int sqlType, final ResultSet rs, final | |||
| return RecordFieldType.RECORD.getDataType(); | |||
| } | |||
|
|
|||
| final String columnName = rs.getMetaData().getColumnName(columnIndex); | |||
There was a problem hiding this comment.
@markap14 In #2386 you added a readerSchema to the ResultSetRecordSet constructor. I was working with this class and do not need this functionality. I've updated the code so that a null readerSchema can be passed, as in my case there is no record reader, just a record writer.
Let me know if you have any concerns. I ran the unit tests for QueryRecord and they all ran without failure.
|
@mattyb149 Code updated. |
|
@mattyb149 Rebased to cleanup version number issues. |
|
@patricker if you can get this working with their Docker image of the Linux build, I might have time to help out. |
|
@MikeThomsen I appreciate that. I've looked at it this docker image, and it looks like it will probably work. I'm not sure if I'll have time, I'll wait and see. |
nifi-assembly/pom.xml
Outdated
| <dependency> | ||
| <groupId>org.apache.nifi</groupId> | ||
| <artifactId>nifi-cdc-mssql-nar</artifactId> | ||
| <version>1.7.0-SNAPSHOT</version> |
There was a problem hiding this comment.
Sorry this has taken so long, can you rebase against the latest master and update the version(s) to 1.8.0-SNAPSHOT? Please and thanks!
There was a problem hiding this comment.
Rebased and version numbers updated. I had some files that I had failed to update from 1.6.0 to 1.7.0, so it wasn't even building correctly as it was... Builds and seems OK now.
|
@mattyb149 Ready when you are. I have plans to add in new functionality to support 'SQL Server Change Tracking', which is a simpler form of change tracking. Would really like to see this PR merged in prior to making any future changes. |
|
can you suggest step by step to build jar file from your NIFI-4521 MS SQL CDC Processor? |
|
@tle-totalwine Just got back from vacation. It looks like in the last 5 months a conflict has arisen, so I'm not sure which version of NiFi this will work with specifically. The conflict looks small, but I would need some time to resolve it. You can build this by checking out the code from Git and running a mvn build for this module. From your command line, navigate to the folder, I'd suggest the root cdc folder: nifi/nifi-nar-bundles/nifi-cdc. From there run a |
|
any update? |
|
@wiardvanrij I've updated the branch. I also have a user who is trying to test this change for me in his environment. |
Thank you, I will start testing it too :) |
|
I will probably need to clean up a Checkstyle violation. I don't get the violation in IntelliJ, but I think I see it and can push a fix. |
|
Hi folks, I will just try to test this branch in my environment too. I will inform news at the next days |
|
Hi @patricker. I am trying to build branch NIFI-4521 and received the errors as showed below. [ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.22.0:test (default-test) on project nifi-persistent-provenance-repository: There are test failures.
|
|
I have been using the MS CDC processor for ~4 months now. I have noticed what I think is a bug in the cdc processor. When I use more than one table in the CDC table list I get an error and no CDC tables are read. The data in the queue below is from removing one of the tables from the list, both tables work independently. I am using nifi v1.10.0, CDC MSSQL v1.9.2
|

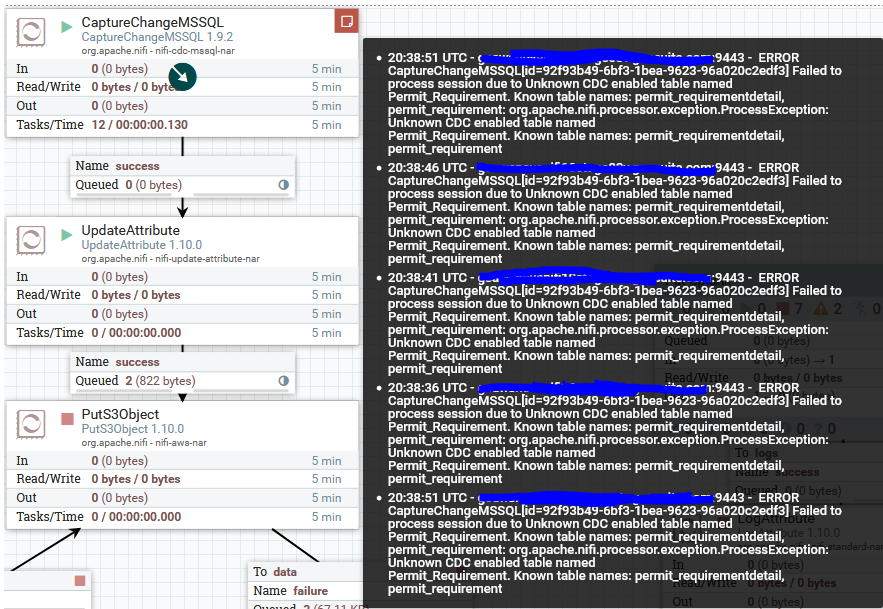
|
@readl1 Out of curiosity, and to maybe make the error message more confusing, can you lower case your table names in the Processor configuration so they will match the ones in the error message? |
|
I figured it out. The issue is not with the case of the table names but when you have a space in the comma separated list. table1, table2, table3 won't work table1,table2,table3 will work |
| final String[] allTables = schemaCache.keySet().toArray(new String[schemaCache.size()]); | ||
|
|
||
| String[] tables = StringUtils | ||
| .split(processContext.getProperty(CDC_TABLES).evaluateAttributeExpressions().getValue(), ","); |
There was a problem hiding this comment.
To the other comment, this might be better handled with a stream split -> trim -> collect in order to handle whitespace between the delimiter and table names
There was a problem hiding this comment.
@mattyb149 I've updated the code, and tweaked a unit test to cover it. What are your thoughts on working towards merging this :) I feel like it's gotten quite a bit of external testing by users at this point.
There was a problem hiding this comment.
@mattyb149 @patricker We still trying to get this merged into master? Anything I can do from the testing standpoint to help that along?
135eb80
to
0dd0d6d
Compare
|
Nice work! When should we expect this to get merged? |
|
@patricker - it sounds like it would be a nice feature to get in based on all the interactions we had here. Can you rebase the pull request against 1.14.0-SNAPSHOT? Are there still open items to fix/rework on this pull request? @mattyb149 - any thoughts? |
|
@pvillard31 There is one open issue related to very large transaction id's not fitting in BigInt. I have not researched it very much, but am already feeling motivated to check it out if this open and active PR might get merged after 3.5 years... I would LOVE to get this merged. I'll take some time tomorrow to check out this one open issue tomorrow. |
|
Yeah I know the feeling, I also have very old PRs that would be nice to have merged. Let me know how it goes with your investigation and we can include it for the next release. |
|
@ravitejatvs @readl1 I've been trying to get binary(10) working, I spent a lot of time on Friday. It's not that it's actually difficult, I found a way to store the binary(10) value as hex. It's that my unit test framework uses Apache DB, and the same functions don't exist in Apache DB that I can tell. Still researching. |
Let me know if I can help at all. I have a DB where I can test this against, a mssql box with the values larger than bigint. |
|
I am starting to see this processor delivery duplicate records. Has @patricker @ravitejatvs seem something similar? Its like the state is not being updated on the next run and it pulls the same data again. |
I wonder if a different timezone is used on the sql server compared to the nifi cluster there could be a loop |
|
@readl1 Hmm. State is one of the last things we save, and if state save fails then we remove the whole file. |
|
What if the cdc data hasn't changed? I have a 2 hour run frequently and
it's not uncommon to have the same data pushed 5 or 6 times.
…On Tue, Mar 16, 2021, 9:41 PM Peter Wicks ***@***.***> wrote:
@readl1 <https://github.com/readl1> Hmm. State is one of the last things
we save, and if state save fails then we remove the whole file.
stateManager.setState(statePropertyMap, Scope.CLUSTER);
session.commit();
} catch (IOException e) {
session.remove(cdcFlowFile);
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#2231 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/ACHJPBPQH4L5SNF7OHMABT3TEACERANCNFSM4EBDBPRA>
.
|
|
@patricker SELECT max(sys.fn_cdc_map_lsn_to_time ( __$start_lsn )) FROM Attribute in nifi: maxvalue.tran_end_time = 2021-03-16 18:17:34.163 Value stored in the state: 2021-03-16 18:17:34.163 How do you compare the current time stored in the state to the time coming from the cdc table? |
|
@readl1 I need to review the code to see what debug options I left in place. Worst case we can add in an option to put the SQL statements into the NiFi log. My email is available on my profile page. Shoot me a message and lets see if we can figure it out. |
|
Had a great meeting with @readl1, and we found the root cause of the issue. It turns out this is caused by a change server-side in MS SQL. Here are the documentation notes from Microsoft:
|
|
We're marking this PR as stale due to lack of updates in the past few months. If after another couple of weeks the stale label has not been removed this PR will be closed. This stale marker and eventual auto close does not indicate a judgement of the PR just lack of reviewer bandwidth and helps us keep the PR queue more manageable. If you would like this PR re-opened you can do so and a committer can remove the stale tag. Or you can open a new PR. Try to help review other PRs to increase PR review bandwidth which in turn helps yours. |
|
Is this version considered working? |
|
@djshura2008 as far as I know it works great still. I changed companies and haven't used it in about a year, but no known issues I'm aware of |
A new Processor + new Bundle for Microsoft SQL Server CDC reading.
Processor works similar to a multi-table QueryDatabaseTable. It stores state on each table, and has some features for handling first run, where it can load snapshots of existing tables, and for handling large change sets.
I created Unit Tests also.
You can read more about Microsoft's table schemas for storing CDC data here:
https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/about-change-data-capture-sql-server
For all changes:
Is there a JIRA ticket associated with this PR? Is it referenced
in the commit message?
Does your PR title start with NIFI-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
Has your PR been rebased against the latest commit within the target branch (typically master)?
Is your initial contribution a single, squashed commit?
For code changes:
For documentation related changes:
Note:
Please ensure that once the PR is submitted, you check travis-ci for build issues and submit an update to your PR as soon as possible.