A Comparison of Two Sensory Panels Trained with Different Feedback Calibration Range Specifications via Sensory Description of Five Beers




Abstract
:1. Introduction
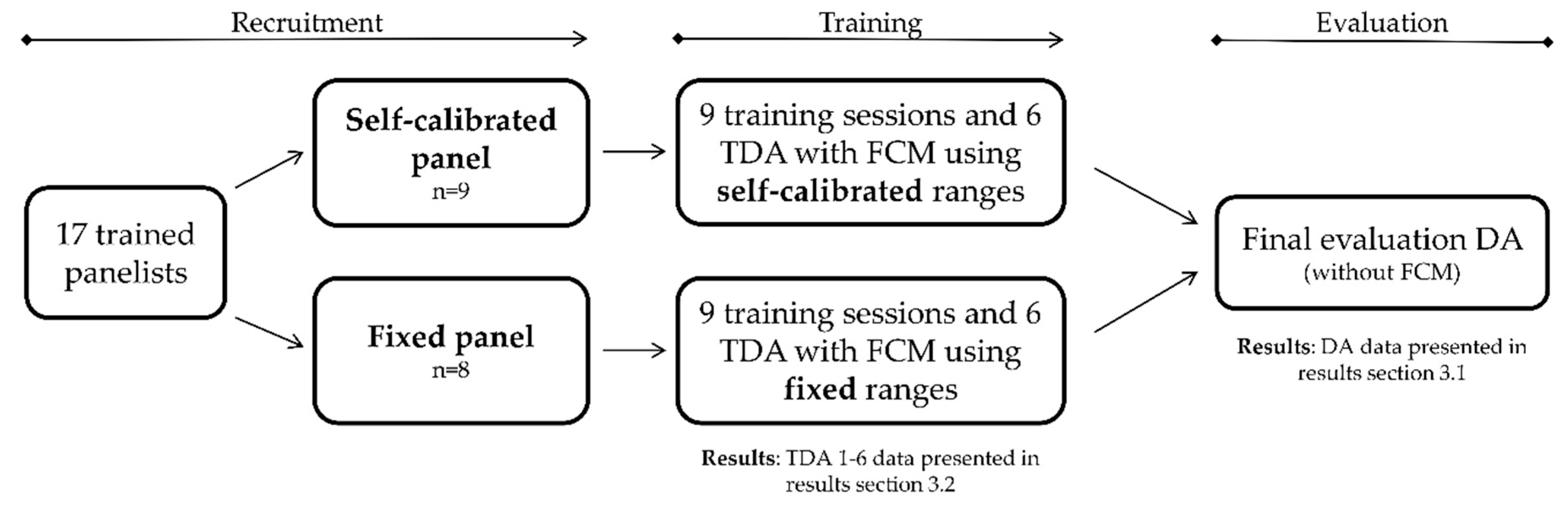
2. Materials and Methods
2.1. Samples
2.2. Descriptive Analysis Panels
2.3. Training Sessions
2.3.1. Application of FCM
2.4. Final Evaluation DA
2.5. Data Analysis Method
2.5.1. Comparison of the Panels’ Positioning of the Samples in the Sensory Space
2.5.2. Comparison of the Panels’ Discriminability and Repeatability
2.5.3. Comparison of the Panels’ Attribute Understanding and Use of Scale
2.5.4. Comparison of the Panels’ Performance Progression over Training Sessions
3. Results
3.1. Comparing the Results of the Descriptive Analysis Evaluation for the Fixed and Self-calibrated Panel
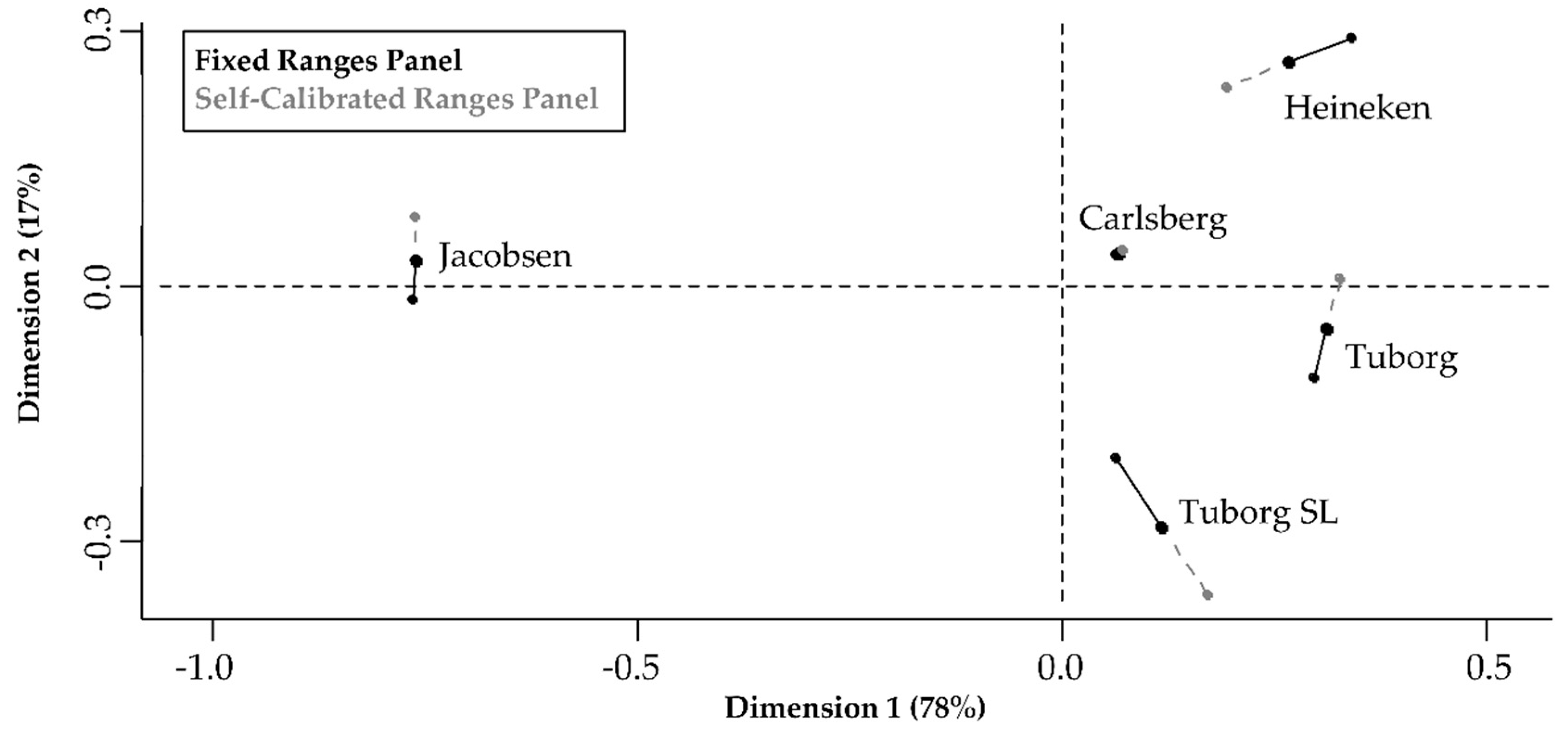
3.1.1. Comparison of the Panels’ Positioning of the Products in the Sensory Space
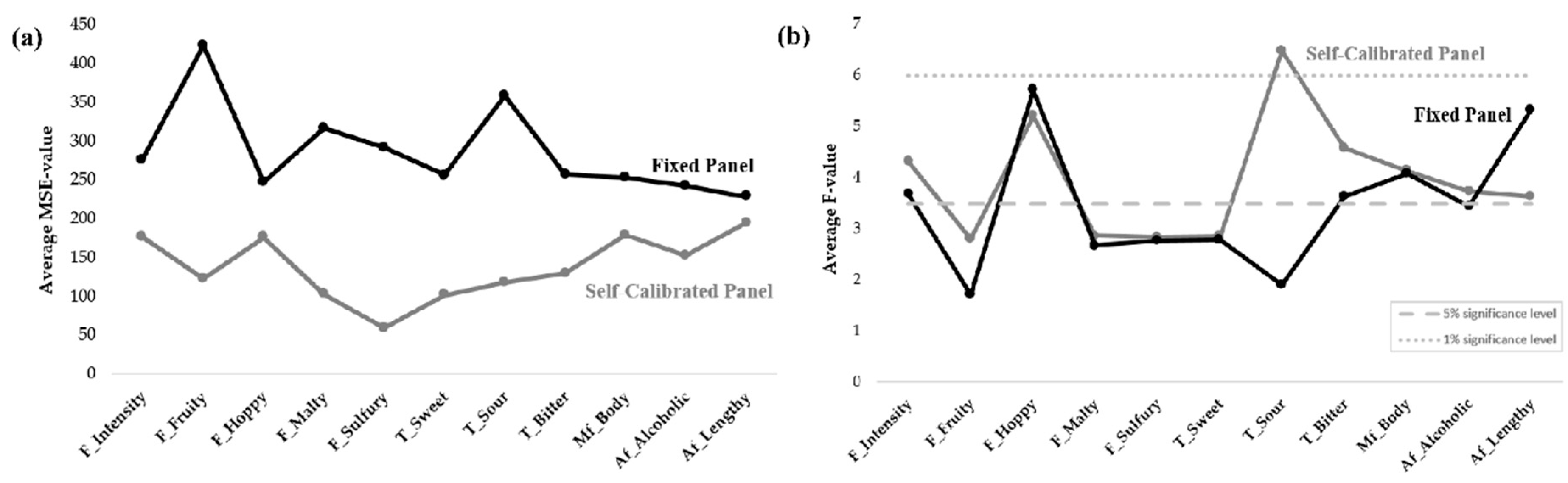
3.1.2. Comparison of the Panels’ Discriminability and Repeatability
3.2. Comparing the Results from Training Sessions, TDA 2 to 6, for the Fixed and Self-calibrated Panel
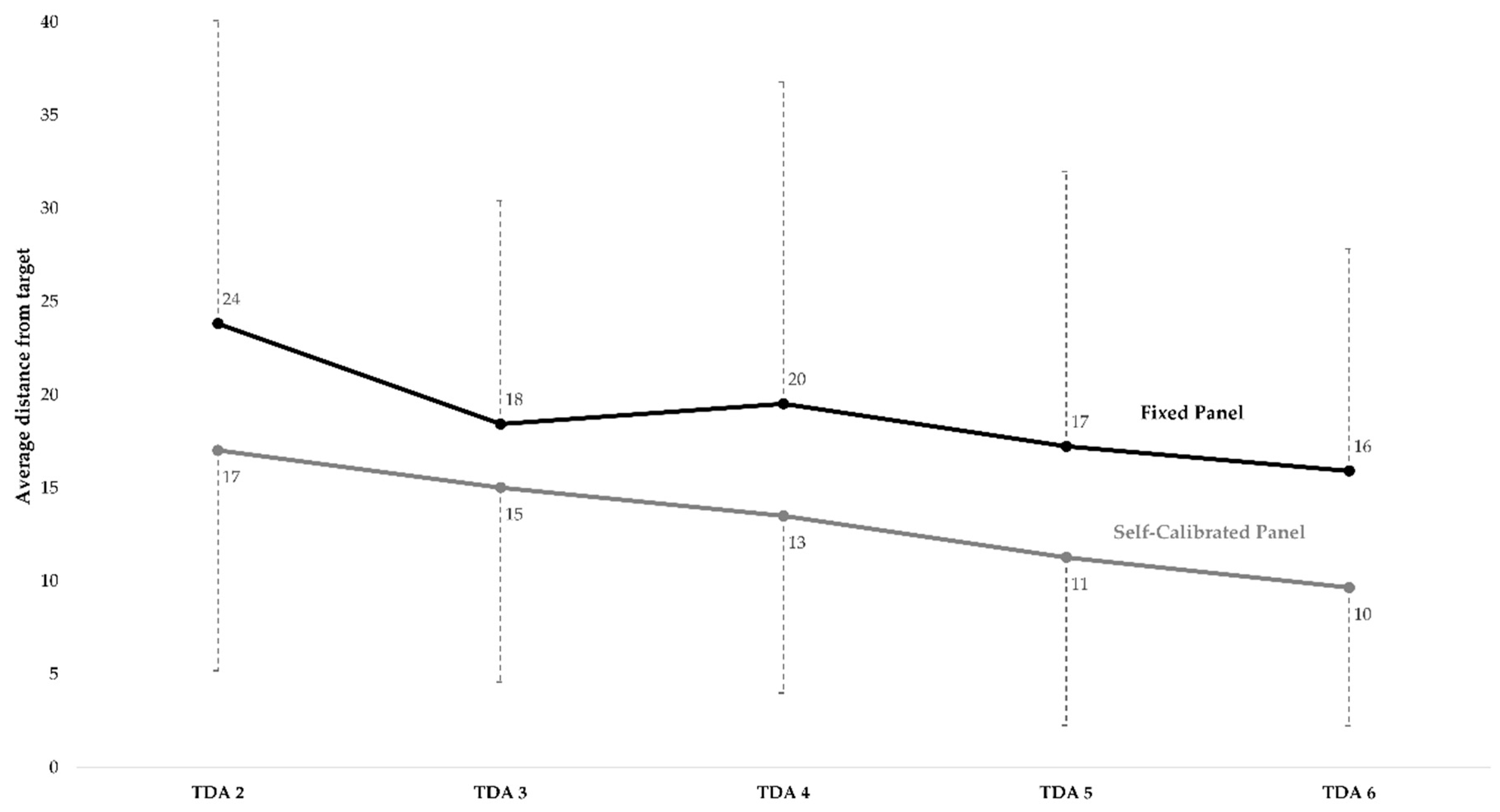
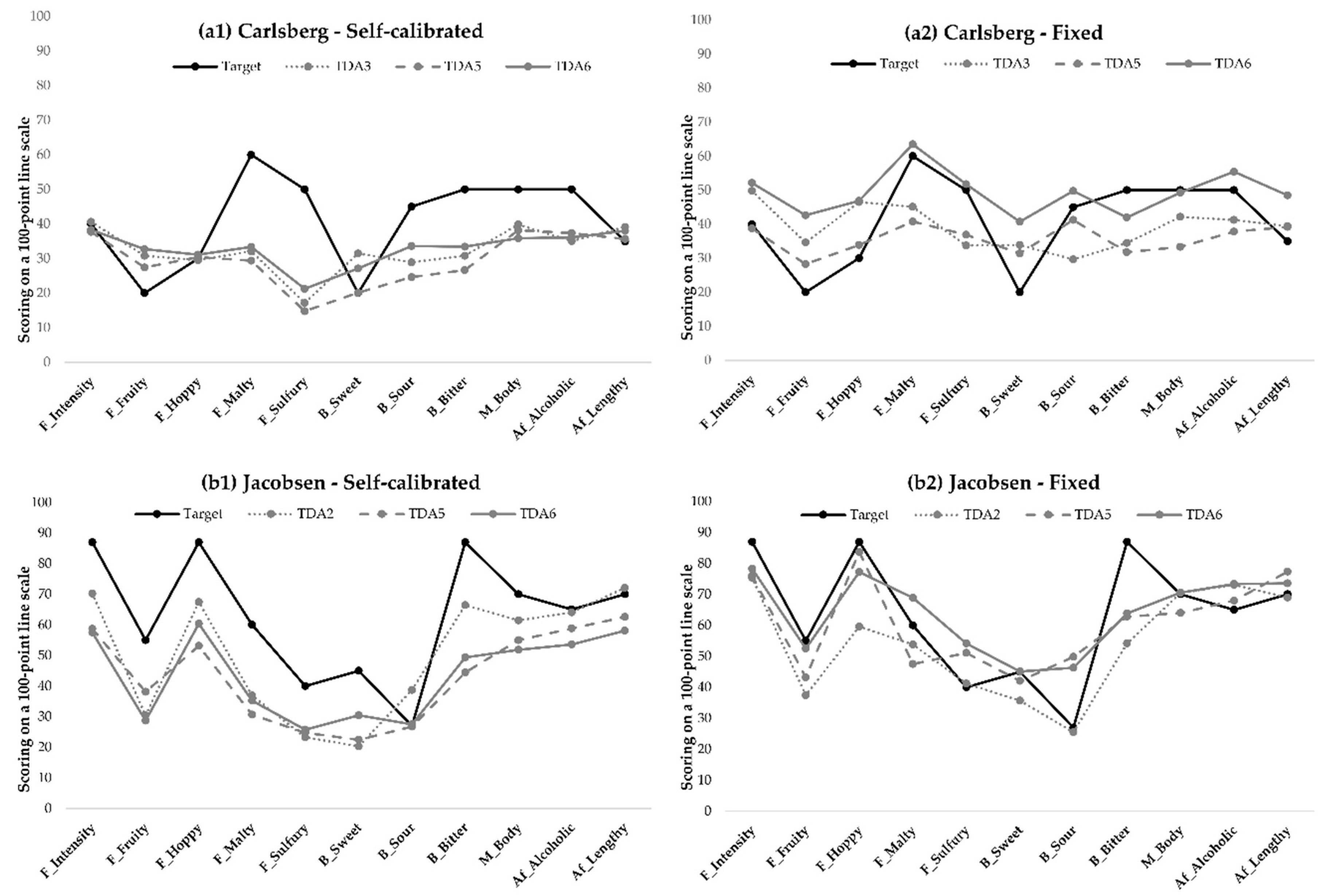
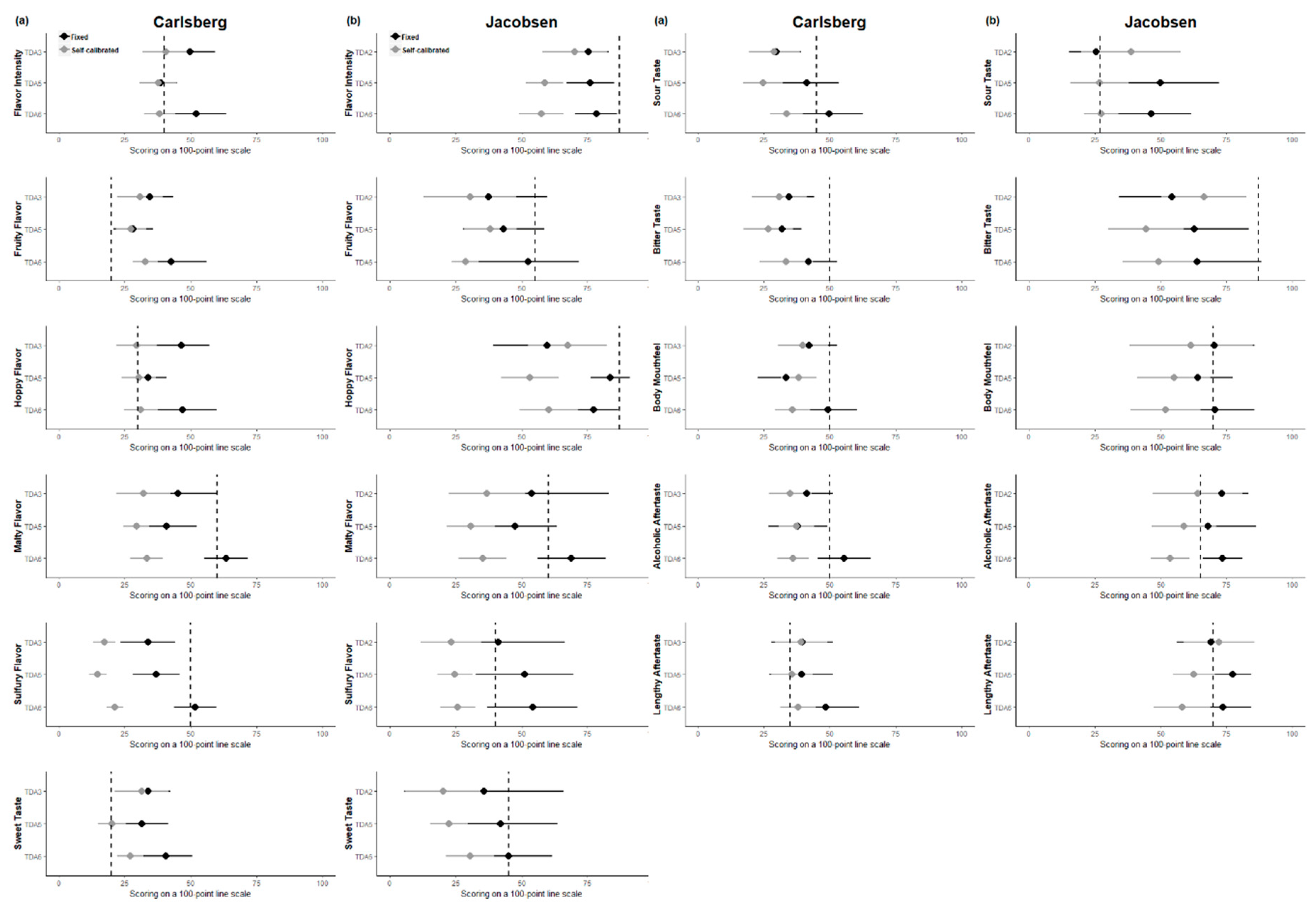
3.2.1. Comparison of the Panels’ Distance from Target Measurements
3.2.2. Comparison of the Panels’ Optimal Target Scores and Panel Means Progression Over Training Sessions
4. Discussion
4.1. The Panels’ Positioning of the Products in the Sensory Space, Their Discriminability, and Repeatability
4.2. The Panels’ Attribute Understanding and Use of Scale During Training
4.3. Comparison of Optimal Target scores and Panel Means Progression over Training Sessions
4.4. Application of FCM and Perceptual Learning Theory
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lawless, H.T.; Heymann, H. Sensory Evaluation of Food: Principles and Practices, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 2010; ISBN 978-1-4419-6487-8. [Google Scholar]
- Meilgaard, M.C.; Civille, G.V.; Carr, B.T. Sensory Evaluation Techniques; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 1999. [Google Scholar]
- Dijksterhuis, G.B.; Byrne, D.V. Does the mind reflect the mouth? Sensory profiling and the future. Crit. Rev. Food Sci. Nutr. 2005, 45, 527–534. [Google Scholar] [CrossRef] [PubMed]
- Murray, J.M.; Delahunty, C.M.; Baxter, I.A. Descriptive sensory analysis: Past, present and future. Food Res. Int. 2001, 34, 461–471. [Google Scholar] [CrossRef]
- Cairncross, S.E.; Sjöström, L.B. Flavor Profiles: A new approach to flavor problems. Food Technol. 1950, 4, 308–311. [Google Scholar]
- Brandt, M.A.; Skinner, E.Z.; Coleman, J.A. Texture Profile Method. J. Food Sci. 1963, 28, 404–409. [Google Scholar] [CrossRef]
- Stone, H.; Sidel, J.L.; Oliver, S.; Woolsey, A.; Singleton, R.C. Sensory analysis by quantitative descriptive analysis. Food Technol. 1974, 8, 24–32. [Google Scholar]
- Stone, H.; Sidel, J.L. Sensory Evaluation Practices, 2nd ed.; Academic Press: Redwood City, CA, USA, 1993. [Google Scholar]
- Elgaard, L.; Jensen, S.; Mielby, L.A.; Byrne, D.V. Performance of beer sensory panels: A comparison of experience level, product knowledge and responsiveness to feedback calibration. J. Sens. Stud. 2019, e12540. [Google Scholar] [CrossRef]
- Elgaard, L.; Mielby, L.A.; Heymann, H.; Byrne, D.V. Effect of product involvement on panels’ vocabulary generation, attribute identification and sample configurations in beer. Foods 2019, 8, 488. [Google Scholar] [CrossRef]
- Bitnes, J.; Rødbotten, M.; Lea, P.; Ueland, Ø.; Martens, M. Effect of product knowledge on profiling performance comparing various sensory laboratories. J. Sens. Stud. 2007, 22, 66–80. [Google Scholar] [CrossRef]
- Chambers, D.H.; Allison, A.-M.A.; Chambers IV, E. Training effects on performance of descriptive panelists. J. Sens. Stud. 2004, 19, 486–499. [Google Scholar] [CrossRef]
- Giacalone, D.; Ribeiro, L.; Frøst, M. Perception and Description of Premium Beers by Panels with Different Degrees of Product Expertise. Beverages 2016, 2, 5. [Google Scholar] [CrossRef]
- Chollet, S.; Valentin, D.; Abdi, H. Do trained assessors generalize their knowledge to new stimuli? Food Qual. Prefer. 2005, 16, 13–23. [Google Scholar] [CrossRef]
- Zamora, M.C.; Guirao, M. Performance comparison between trained assessors and wine experts using specific sensory attributes. J. Sens. Stud. 2004, 19, 530–545. [Google Scholar] [CrossRef]
- Byrne, D.V.; Bak, L.S.; Bredie, W.L.P.; Bertelsen, G.; Martens, M. Development of a sensory vocabulary for warmed-over flavor: Part I. In porcine meat. J. Sens. Stud. 1999, 14, 47–65. [Google Scholar] [CrossRef]
- Drake, M.A.; Civille, G.V. Flavor Lexicons. Compr. Rev. Food Sci. Food Saf. 2002, 2, 33–40. [Google Scholar] [CrossRef]
- Lawless, L.J.R.; Civille, G.V. Developing lexicons: A review. J. Sens. Stud. 2013, 28, 270–281. [Google Scholar] [CrossRef]
- Byrne, D.V.; Bredie, W.L.P.; Martens, M. Development of a sensory vocabulary for warmed-over flavor: Part II. In chicken meat. J. Sens. Stud. 1999, 14, 67–78. [Google Scholar] [CrossRef]
- Suwonsichon, S. The importance of sensory lexicons for research and development of food products. Foods 2019, 8, 27. [Google Scholar] [CrossRef]
- Yang, J.; Lee, J. Application of sensory descriptive analysis and consumer studies to investigate traditional and authentic foods: A review. Foods 2019, 8, 54. [Google Scholar] [CrossRef]
- Tran, T.; James, M.N.; Chambers, D.; Koppel, K.; Chambers IV, E. Lexicon development for the sensory description of rye bread. J. Sens. Stud. 2019, 34, e12474. [Google Scholar] [CrossRef]
- Chambers IV, E.; Sanchez, K.; Phan, U.X.T.; Miller, R.; Civille, G.V.; Di Donfrancesco, B. Development of a “living” lexicon for descriptive sensory analysis of brewed coffee. J. Sens. Stud. 2016, 31, 465–480. [Google Scholar] [CrossRef]
- Dijksterhuis, G. Assessing Panel Consonance. Food Qual. Prefer. 1995, 6, 7–14. [Google Scholar] [CrossRef]
- Martens, M.; Bredie, W.L.; Martens, H. Sensory profiling data studied by partial least squares regression. Food Qual. Prefer. 2000, 11, 147–149. [Google Scholar] [CrossRef]
- Qannari, E.M.; MacFie, H.J.H.; Courcoux, P. Performance indices and isotropic scaling factors in sensory profiling. Food Qual. Prefer. 1999, 10, 17–21. [Google Scholar] [CrossRef]
- Tomic, O.; Nilsen, A.; Martens, M.; Næs, T. Visualization of sensory profiling data for performance monitoring. LWT Food Sci. Technol. 2007, 40, 262–269. [Google Scholar] [CrossRef]
- Goldstone, R.L. Perceptual learning. Annu. Rev. Psychol. 1998, 49, 585–612. [Google Scholar] [CrossRef]
- Bangert-Drowns, R.L.; Kulik, C.-L.C.; Kulik, J.A.; Morgan, M. The Instructional Effect of Feedback in Test-Like Events. Rev. Educ. Res. 1991, 61, 213–238. [Google Scholar] [CrossRef]
- Herzog, M.H.; Fahle, M. The role of feedback in learning a vernier discrimination task. Vis. Res. 1997, 37, 2133–2141. [Google Scholar] [CrossRef] [Green Version]
- Kulik, J.A.; Kulik, C.-L.C. Timing of Feedback and Verbal Learning. Rev. Educ. Res. 1988, 58, 79–97. [Google Scholar] [CrossRef]
- Shute, V.J. Focus on Formative Feedback. Rev. Educ. Res. 2008, 78, 153–189. [Google Scholar] [CrossRef]
- Trowbridge, M.H.; Cason, H. An experimental study of thorndike’s theory of learning. J. Gen. Psychol. 1932, 7, 245–260. [Google Scholar] [CrossRef]
- Walk, R.D. Perceptual learning and the discrimination of wines. Psychon. Sci. 1966, 5, 57–58. [Google Scholar] [CrossRef]
- Spence, C. Perceptual learning in the chemical senses: A review. Food Res. Int. 2019, 123, 746–761. [Google Scholar] [CrossRef] [PubMed]
- Lestringant, P.; Delarue, J.; Heymann, H. 2010–2015: How have conventional descriptive analysis methods really been used? A systematic review of publications. Food Qual. Prefer. 2019, 71, 1–7. [Google Scholar] [CrossRef]
- Kluger, A.N.; DeNisi, A. The effects of feedback interventions on performance: A historical review, a meta-analysis, and a preliminary feedback intervention theory. Psychol. Bull. 1996, 119, 254–284. [Google Scholar] [CrossRef]
- Kulhavy, R.W.; Wager, W. Feedback in programmed instruction: Historical context and implications for practice. In Interactive Instruction and Feedback; Dempsey, J.V., Sales, G.C., Eds.; Educational Technology Publications Inc.: Englewood, NJ, USA, 1993; pp. 3–20. [Google Scholar]
- Findlay, C.J.; Castura, J.C.; Schlich, P.; Lesschaeve, I. Use of feedback calibration to reduce the training time for wine panels. Food Qual. Prefer. 2006, 17, 266–276. [Google Scholar] [CrossRef]
- Findlay, C.J.; Castura, J.C.; Lesschaeve, I. Feedback calibration: A training method for descriptive panels. Food Qual. Prefer. 2007, 18, 321–328. [Google Scholar] [CrossRef]
- Richards, M.; De Kock, H.L.; Buys, E.M. Multivariate accelerated shelf-life test of low fat UHT milk. Int. Dairy J. 2014, 36, 38–45. [Google Scholar] [CrossRef] [Green Version]
- Acevedo, W.; Capitaine, C.; Rodríguez, R.; Araya-Durán, I.; González-Nilo, F.; Pérez-Correa, J.R.; Agosin, E. Selecting optimal mixtures of natural sweeteners for carbonated soft drinks through multi-objective decision modeling and sensory validation. J. Sens. Stud. 2018, 33, e12466. [Google Scholar] [CrossRef]
- Espinoza, M.I.; Vincken, J.P.; Sanders, M.; Castro, C.; Stieger, M.; Agosin, E. Identification, quantification, and sensory characterization of teviol glycosides from differently processed stevia rebaudiana commercial extracts. J. Agric. Food Chem. 2014, 62, 11797–11804. [Google Scholar] [CrossRef]
- Chang, A.C.; Dando, R. Exposure to light-emitting diodes may be more damaging to the sensory properties of fat-free milk than exposure to fluorescent light. J. Dairy Sci. 2018, 101, 154–163. [Google Scholar] [CrossRef]
- Martin, N.; Carey, N.; Murphy, S.; Kent, D.; Bang, J.; Stubbs, T.; Wiedmann, M.; Dando, R. Exposure of fluid milk to LED light negatively affects consumer perception and alters underlying sensory properties. J. Dairy Sci. 2016, 99, 4309–4324. [Google Scholar] [CrossRef] [Green Version]
- Fisher, C.M.; King, S.K.; Castura, J.C.; Findlay, C.J. Does data collection device affect sensory descriptive analysis results? J. Sens. Stud. 2016, 31, 275–282. [Google Scholar] [CrossRef]
- Obst, K.; Paetz, S.; Backes, M.; Reichelt, K.V.; Ley, J.P.; Engel, K.-H. Evaluation of unsaturated alkanoic acid amides as maskers of epigallocatechin gallate astringency. J. Agric. Food Chem. 2013, 61, 4242–4249. [Google Scholar] [CrossRef] [PubMed]
- Bavay, C.; Symoneaux, R.; Maître, I.; Kuznetsova, A.; Brockhoff, P.B.; Mehinagic, E. Importance of fruit variability in the assessment of apple quality by sensory evaluation. Postharvest Biol. Technol. 2013, 77, 67–74. [Google Scholar] [CrossRef]
- Pietrasik, Z.; Wang, H.; Janz, J.A.M. Effect of canola oil emulsion injection on processing characteristics and consumer acceptability of three muscles from mature beef. Meat Sci. 2013, 93, 322–328. [Google Scholar] [CrossRef] [PubMed]
- Mahan, E.D.; Morrow, K.M.; Hayes, J.E. Quantitative perceptual differences among over-the-counter vaginal products using a standardized methodology: Implications for microbicide development. Contraception 2011, 84, 184–193. [Google Scholar] [CrossRef]
- Williams, E.J. Experimental designs balanced for the estimation of residual effects of treatments. Aust. J. Sci. Res. 1949, 2, 149–168. [Google Scholar] [CrossRef]
- Gower, J.C. Generalized procrustes analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Le, S.; Josse, J.; Husson, F. FactoMineR: An R package for multivariate analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef]
- Xiong, R.; Blot, K.; Meullenet, J.F.; Dessirier, J.M. Permutation tests for generalized procrustes analysis. Food Qual. Prefer. 2008, 19, 146–155. [Google Scholar] [CrossRef]
- Dijksterhuis, G. Multivariate data analysis in sensory and consumer science: An overview of developments. Trends Food Sci. Technol. 1995, 6, 206–211. [Google Scholar] [CrossRef]
- Hervé, M. RVAideMemoire: Testing and Plotting Procedures for Biostatistics. Available online: https://CRAN.R-project.org/package=RVAideMemoire (accessed on 12 October 2019).
- Castura, J.C.; Findlay, C.J.; Lesschaeve, I. Monitoring calibration of descriptive sensory panels using distance from target measurements. Food Qual. Prefer. 2005, 16, 682–690. [Google Scholar] [CrossRef]
- Lenth, R.; Singmann, H.; Love, J.; Buerkner, P.; Hervé, M. emmeans: Estimated Marginal Means, aka Least-Squares Means. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 31 October 2019).
- Piepho, H.P. An algorithm for a letter-based representation of all-pairwise comparisons. J. Comput. Graph. Stat. 2004, 13, 456–466. [Google Scholar] [CrossRef]
- Mangiafico, S. rcompanion: Functions to Support Extension Education Program Evaluation. Available online: https://CRAN.R-project.org/package=rcompanion (accessed on 31 October 2019).
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | Product name | Sample code | Beer type | ABV | Session |
| Tuborg Gold | Gold | Strong Pilsner | 5.6 | T | |
| Budweiser | Budweiser | Strong Pilsner | 5.0 | T | |
| Carlsberg Elephant | Elephant | Strong Pilsner | 7.2 | T | |
| Carlsberg Nordic Golden | Nordic | Pilsner, Alcohol free | 0.5 | T | |
| Tuborg Green | Tuborg | Pilsner | 4.6 | T, TDA, and E | |
| Carlsberg Pilsner | Carlsberg | Pilsner | 4.6 | T, TDA, and E | |
| Jacobsen Extra Pilsner | Jacobsen | Pilsner, Special brew | 5.5 | T, TDA, and E | |
| Tuborg Super Light | Tuborg SL | Pilsner, Alcohol free | 0.09 | T, TDA, and E | |
| Heineken | Heineken | Pilsner | 4.6 | T, TDA, and E | |
| (b) | Modality | Attribute | Minimum Intensity (0–25 on 100-point scale) | Maximum Intensity (75–100 on 100-point scale) | |
| Flavor (F) | Intensity | Tuborg SL | Jacobsen | ||
| Flavor (F) | Fruity | Carlsberg | Gold | ||
| Flavor (F) | Malty | Budweiser | Elephant | ||
| Flavor (F) | Hoppy | Tuborg SL | Jacobsen | ||
| Flavor (F) | Sulfury | Tuborg SL | Elephant | ||
| Basic Taste (T) | Sweetness | Carlsberg | Nordic | ||
| Basic Taste (T) | Sourness | Nordic | Tuborg SL | ||
| Basic Taste (T) | Bitterness | Budweiser | Jacobsen | ||
| Mouthfeel (Mf) | Body | Tuborg SL | Elephant | ||
| Aftertaste (Af) | Alcoholic | Nordic | Elephant | ||
| Aftertaste (Af) | Lingering | Tuborg SL | Jacobsen | ||
| (a) | Session | Description of activity | ||||||
| T1 | 1. | Presentation of basic taste solutions in DI water 1: sweet, sour, bitter, and salty. | ||||||
| 2. | Presentation of spiked beer samples. 2 | |||||||
| 3. | Comparison between basic taste solutions and spiked samples. | |||||||
| T2 | 1. | Presentation of spiked beer samples. | ||||||
| 2. | Presentation of beer reference frame for attribute minima and maxima. 3 | |||||||
| 3. | Comparison between spiked samples and reference samples. | |||||||
| T3 | 1. | Repetition of beer reference frame and reference samples. | ||||||
| 2. | Booth evaluation: TDA 4 1. | |||||||
| T4 | 1. | Individual evaluation of three beer samples, Jacobsen (1 rep) and Tuborg SL (2 rep), on paper ballots. | ||||||
| 2. | Discussion of results in reference to placing the samples on four sections of the scale: low = 0–25%, medium-low = 25–50%, medium-high = 50–75%, high = 75–100%. | |||||||
| T5 | 1. | Repetition of beer reference frame and reference samples. | ||||||
| 2. | Booth evaluation: TDA 2. | |||||||
| T6 | 1. | Individual generation of word associations for the different attributes on paper ballots. | ||||||
| 2. | Discussion of word associations in plenum. | |||||||
| 3. | Booth evaluation: TDA 3. | |||||||
| T7 | 1. | Repetition of word associations. | ||||||
| 2. | Repetition of beer reference frame and reference samples. | |||||||
| 3. | Comparison between reference samples and spiked samples (instructed to exclude intensity). | |||||||
| 4. | Booth evaluation: TDA 4. | |||||||
| T8 | 1. | Presentation and discussion of results from TDA 4. | ||||||
| 2. | In booth: quiz with identification of reference samples. Low and high attribute intensity sample presented for each attribute, and panelists had to indicate which sample was respectively high and low in the particular attribute. | |||||||
| 3. | Booth evaluation: TDA 5. | |||||||
| T9 | 1. | Repetition of beer reference frame and reference samples. | ||||||
| 2. | Booth evaluation: TDA 6. | |||||||
| (b) | Product name | TDA 1 | TDA 2 | TDA 3 | TDA 4 | TDA 5 | TDA 6 | |
| Tuborg | 1 rep 5 | 1 rep * | 2 rep * | 1 rep | 2 rep * | |||
| Carlsberg | 1 rep | 2 rep * | 2 rep * | 2 rep * | ||||
| Jacobsen | 1 rep | 1 rep * | 1 rep * | |||||
| Tuborg SL | 1 rep | 1 rep * | 2 rep * | 1 rep * | ||||
| Heineken | 1 rep | 1 rep | 1 rep * | 1 rep | ||||
| Fixed | Self-Calibrated | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| TDA 2 | TDA 3 | TDA 4 | TDA 5 | TDA 6 | TDA 2 | TDA 3 | TDA 4 | TDA 5 | TDA 6 | ||
| Flavor | Intensity | 38.6 | 14.4 | 20.1 | 15.0 | 13.2 | 22.7 | 14.6 | 12.9 | 9.0 | 8.5 |
| + | ÷ | + | + | + | + | + | + | ||||
| Fruit | 14.5 | 21.2 | 15.5 | 11.8 | 22.2 | 8.9 | 12.7 | 8.7 | 11 | 8.6 | |
| ÷ | + | + | ÷ | ÷ | + | ÷ | + | ||||
| Hoppy | 28.3 | 18.9 | 21.3 | 12.9 | 14.6 | 27.3 | 15.8 | 14.6 | 13.0 | 9.8 | |
| + | ÷ | + | ÷ | + | + | + | + | ||||
| Malt | 26.7 | 20.3 | 12.3 | 14.3 | 14.0 | 26.2 | 13.8 | 15.2 | 11.5 | 9.0 | |
| + | + | ÷ | = | + | ÷ | + | + | ||||
| Sulfury | 13.1 | 16.9 | 13.5 | 15.7 | 12.8 | 14.4 | 11.5 | 14.5 | 6.5 | 5.7 | |
| ÷ | + | ÷ | + | + | ÷ | + | + | ||||
| Basic Taste | Sweet | 14.4 | 16.4 | 14.2 | 14.4 | 18.6 | 11.8 | 20.5 | 9.7 | 8.8 | 9.2 |
| ÷ | + | = | ÷ | ÷ | + | + | = | ||||
| Sour | 36.8 | 19.3 | 27.3 | 23.5 | 17.4 | 19.1 | 17.8 | 14.5 | 12.6 | 9.4 | |
| + | ÷ | + | + | + | + | + | + | ||||
| Bitter | 23.7 | 22.1 | 13.8 | 23.0 | 19.5 | 19.2 | 16.4 | 17.1 | 19.2 | 13.8 | |
| + | + | ÷ | + | + | ÷ | ÷ | + | ||||
| Mouthfeel | Body | 24.1 | 16.3 | 23.9 | 20.8 | 13.9 | 17.2 | 14.8 | 14.1 | 10.7 | 12.1 |
| + | ÷ | + | + | + | + | + | + | ||||
| Aftertaste | Alcoholic | 14.3 | 18.0 | 24.5 | 20.6 | 13.4 | 9.7 | 13.8 | 13.4 | 9.7 | 9.4 |
| ÷ | ÷ | + | + | ÷ | = | + | = | ||||
| Lingering | 16.8 | 19.0 | 28.3 | 17.5 | 15.6 | 18.1 | 13.4 | 14.0 | 11.9 | 10.7 | |
| ÷ | ÷ | + | + | + | ÷ | + | + | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elgaard, L.; Mielby, L.A.; Hopfer, H.; Byrne, D.V. A Comparison of Two Sensory Panels Trained with Different Feedback Calibration Range Specifications via Sensory Description of Five Beers. Foods 2019, 8, 534. https://doi.org/10.3390/foods8110534
Elgaard L, Mielby LA, Hopfer H, Byrne DV. A Comparison of Two Sensory Panels Trained with Different Feedback Calibration Range Specifications via Sensory Description of Five Beers. Foods. 2019; 8(11):534. https://doi.org/10.3390/foods8110534
Chicago/Turabian StyleElgaard, Line, Line A. Mielby, Helene Hopfer, and Derek V. Byrne. 2019. "A Comparison of Two Sensory Panels Trained with Different Feedback Calibration Range Specifications via Sensory Description of Five Beers" Foods 8, no. 11: 534. https://doi.org/10.3390/foods8110534